
An operations platform for monitoring application health, managing incidents, and communicating service status. Built from the initial system design through production deployment.
- Role
- Product strategy, design, engineering
- Timeline
- 2026 to present
- Status
- Active
- Platform
- Web SaaS
Our role
End-to-end product ownership.
StackPulse was built in-house rather than for a client. The work covered the complete product, from initial requirements and design through deployment and documentation.
- Product strategy
- User experience
- Interface design
- Frontend engineering
- Backend engineering
- Database design
- Authentication and security
- Monitoring architecture
- Deployment
- Documentation
Background
Why we built StackPulse.
StackPulse addresses a recurring operational problem: teams need to know when applications fail, understand what changed, and communicate service health without stitching together a large collection of tools.
Addressing that problem required more than a dashboard. The system needed safe outbound monitoring, durable check history, clear incident transitions, configurable notifications, live interface updates, public status reporting, and security boundaries around user-supplied credentials and URLs.
Building the complete product required balancing product scope, data design, interface clarity, operational reliability, and long-term maintainability.
Key features
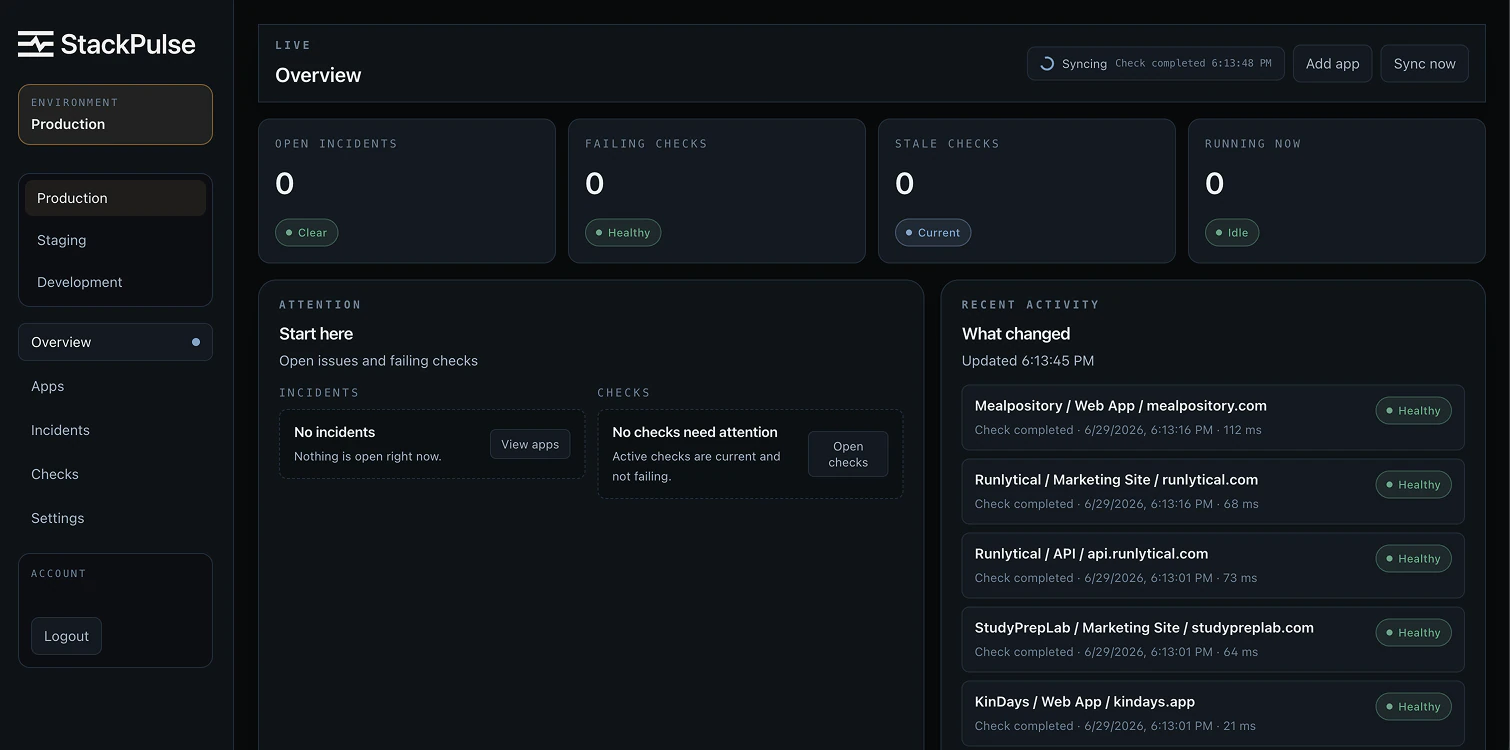
Monitoring and incident workflows.
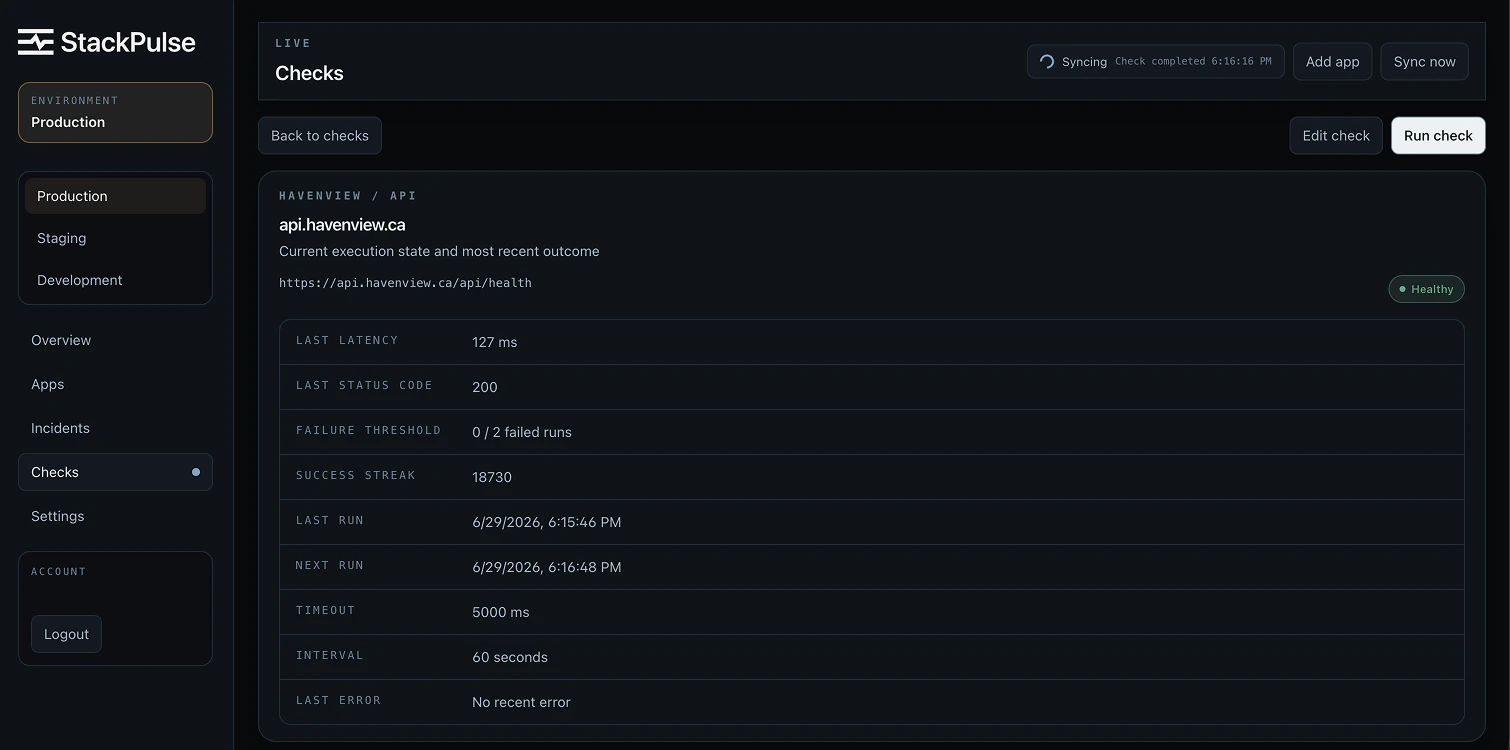
Health checks
Scheduled GET and HEAD checks support status, content, timeout, retry, and recovery rules.
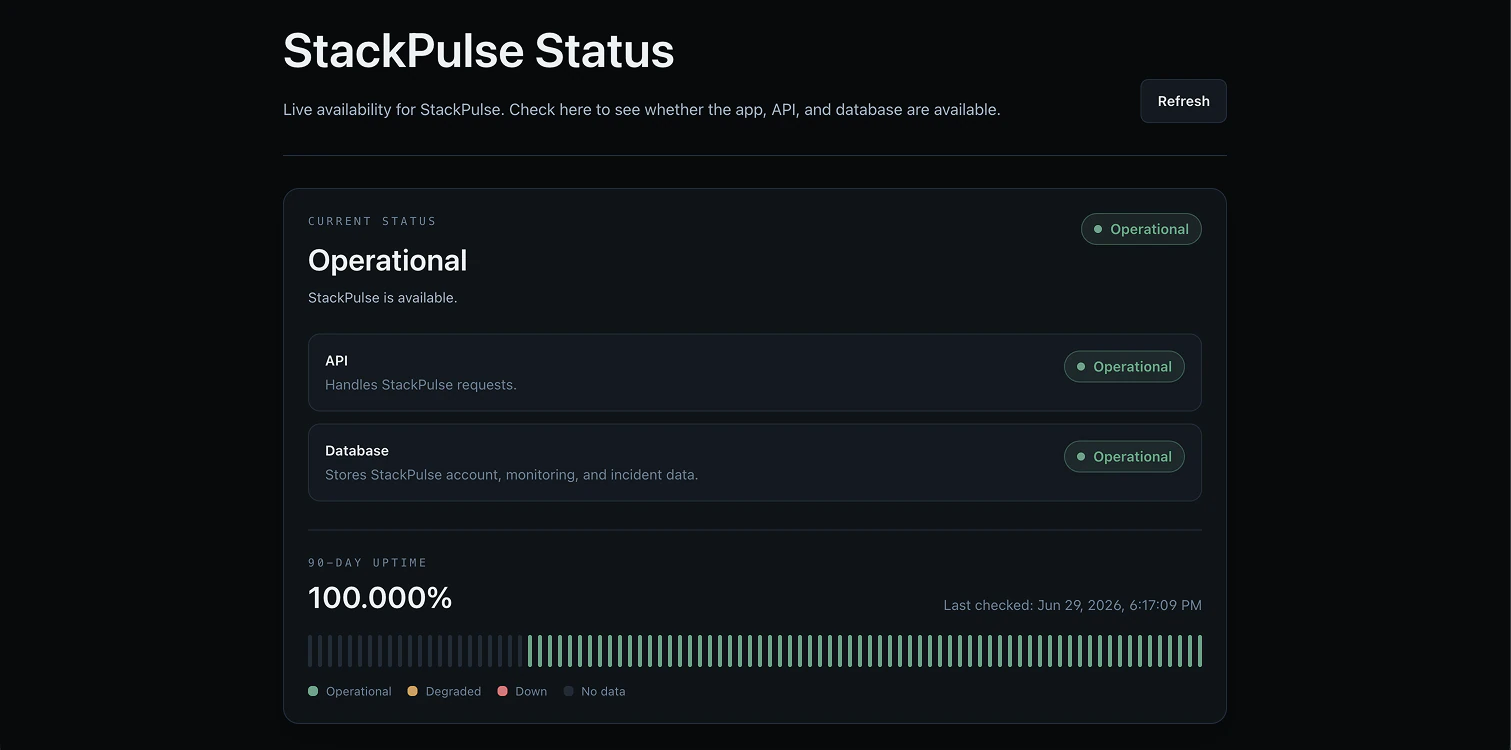
Public status pages
A clear public view communicates current service health and uptime history.
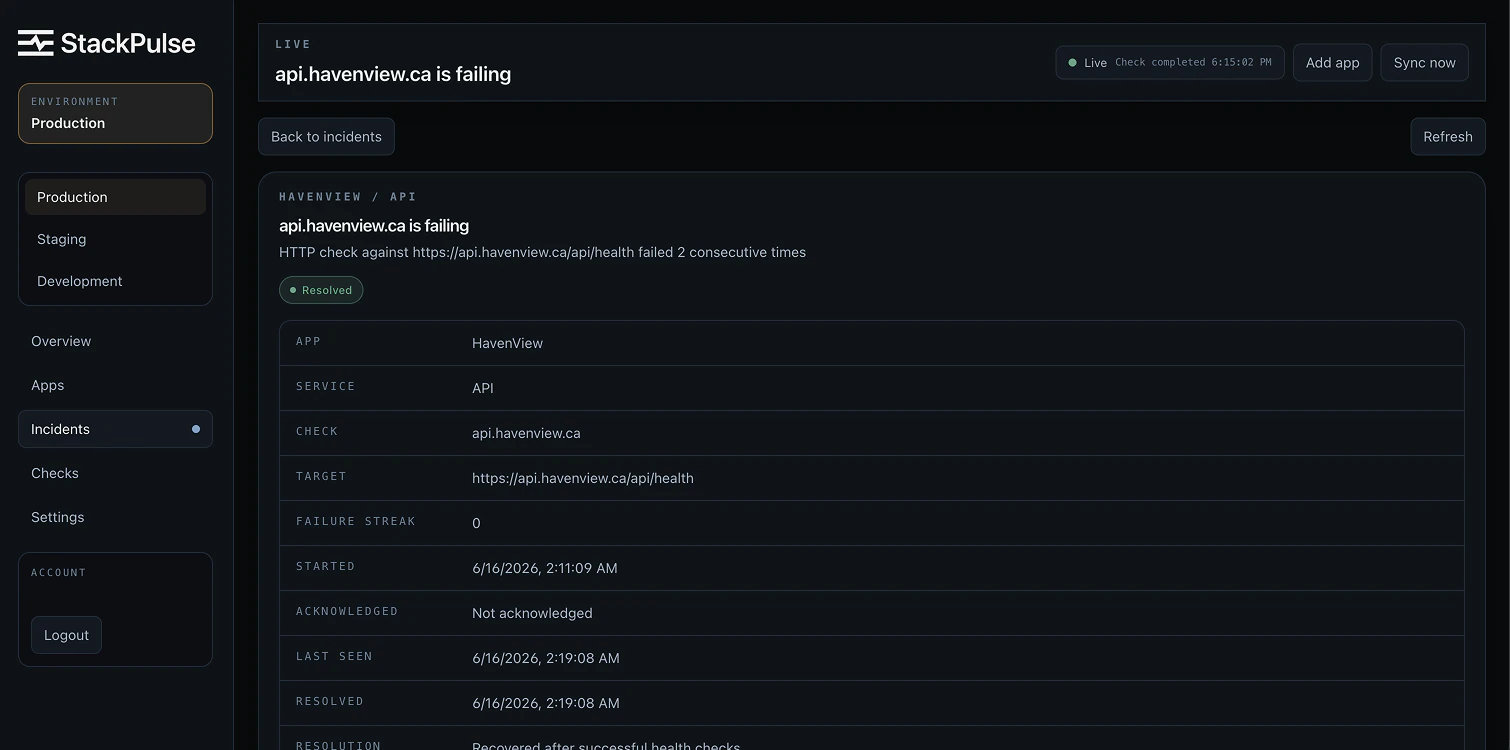
Incident management
Failures become traceable incidents with acknowledgement, watching, and automatic resolution.
Email notifications
Configurable email routing keeps the right people informed when checks fail or recover.
Discord notifications
Webhook alerts bring incident updates into the channels teams already monitor.
Environment management
Production, staging, and development systems remain organized without losing context.
Uptime history
Historical check results make reliability visible beyond the current moment.
Response-time analysis
Latency history helps teams identify slow services and emerging performance issues.
Engineering decisions.
The architecture keeps critical behaviour explicit, testable, and supportable. Each boundary has a specific operational purpose.
Separated application boundaries
The dashboard, public status site, API, and documentation deploy as distinct applications while sharing one typed domain package. Each surface can evolve without coupling unrelated concerns.
Custom authentication model
Custom HMAC bearer sessions keep the authentication model narrow and auditable. Passwords use scrypt, while reset tokens are hashed, expiring, and single-use.
Explicit SQL over an ORM
Handwritten queries and versioned migrations make indexes, joins, transactions, and operational history visible. PostgreSQL provides durable relational constraints and predictable query behaviour.
Bounded monitoring work
The scheduler applies timeouts, retries, concurrency limits, response-size limits, and failure thresholds before creating or resolving incidents.
Protected outbound requests
URL validation, SSRF protection, encrypted credentials, account limits, and secret sanitization reduce risk where user-configured checks interact with external systems.
Live interface updates
Server-Sent Events update operational views without a heavier real-time layer. Shared components keep status, incident, and check states consistent across responsive interfaces.
Product screenshots.
Dense technical information is organized around the action an operator needs to take: inspect a check, understand an incident, or confirm public service health.
Implementation
Technical stack.
The project uses a relatively small set of established tools. The dependencies are straightforward, and each part of the stack has a clear role in the system.
- Core
- TypeScriptNode.js 22PostgreSQL 16npm workspacesDocker
- Web
- React 19Vite 8Tailwind CSS 4Server-Sent Events
- API
- Express 5ZodPinoHandwritten SQL
- Database
- PostgreSQLCustom SQL migrations
- Authentication
- HMAC bearer sessionsscrypt password hashingAES-256-GCM encryption
- Notifications
- ResendDiscord webhooks
- Tooling
- TypeScript strict modetsxNode.js test runner
Why this project matters.
StackPulse moved from a product idea to a system that runs continuously. The work included defining requirements, handling failures, supporting users, and maintaining the platform after deployment.
- 01System boundaries based on monitoring, incident, alert, and reporting workflows.
- 02Security and reliability defined as core system requirements.
- 03Code and data organized so changes remain easier to trace and test.
- 04Operational requirements reflected in the interface design.
- 05Performance, accessibility, testing, and documentation included in implementation.
Summary
What this project demonstrates.
Building StackPulse required many of the same architectural, operational, and product decisions found in custom software projects—from defining system boundaries and protecting sensitive data to modelling business rules and operating software in production. Those experiences directly inform how we approach client work.
Have a software system that needs clearer structure?
Tell us what your team is trying to operate, improve, or understand.